Vizgen Mouse Liver Squidpy Vignette
This vignette shows how to use Squidpy and Scanpy to analyze MERFISH data from the Vizgen MERFISH Mouse Liver Map. This notebook analyzes the Liver1Slice1 MERFISH dataset that measures 347 genes across over >300,000 liver cells in a single mouse liver slice.
from copy import deepcopy
import numpy as np
import pandas as pd
from scipy.cluster import hierarchy as sch
from matplotlib import pyplot as plt
import scanpy as sc
import squidpy as sq
%matplotlib inline
Single-Cell Clustering of Vizgen MERFISH Mouse Liver Data
Obtain Data from Vizgen
We will use the Liver1Slice1 dataset from Vizgen’s MERFISH Mouse Liver Map: https://info.vizgen.com/mouse-liver-access. In order to run this tutorial we will download the cell_by_gene.csv and meta_cell.csv. Please follow the instructions to obtain access to the showcase data and download the data - here we save the data to a directory called tutorial_data/ in the same directory as this notebook.
# confirm the contents of the directory tutorial_data
!ls tutorial_data/
Liver1Slice1_cell_by_gene.csv Liver1Slice1_cell_metadata.csv
Load MERFISH Data into AnnData Object
First, we load the cell-by-gene and cell-metadata CSVs and construct an AnnData object adata.
adata = sq.read.vizgen(
"tutorial_data",
counts_file="Liver1Slice1_cell_by_gene.csv",
meta_file="Liver1Slice1_cell_metadata.csv",
)
adata
AnnData object with n_obs × n_vars = 395215 × 385
obs: 'fov', 'volume', 'min_x', 'max_x', 'min_y', 'max_y'
uns: 'spatial'
obsm: 'spatial'
Make gene names unique and calculate QC metrics
adata.var_names_make_unique()
adata.var["mt"] = adata.var_names.str.startswith("mt-")
sc.pp.calculate_qc_metrics(
adata, qc_vars=["mt"], percent_top=(50, 100, 200, 300), inplace=True
)
OMP: Info #270: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
Filter cells with low expression and genes that are expressed in too few cells.
sc.pp.filter_cells(adata, min_counts=50)
sc.pp.filter_genes(adata, min_cells=10)
Data Pre-processing
Here we use Scanpy total-count normalize, logarithmize, and scale gene expression to unit variance (clipping values that exceed 10 standard deviations).
print("normalize total")
sc.pp.normalize_total(adata)
print("log transform")
sc.pp.log1p(adata)
print("scale")
sc.pp.scale(adata, max_value=10)
normalize total
log transform
scale
Dimensionality Reduction, Neighbor Calculation, and Clustering
Here we use Scanpy to: reduce the dimensionality of our data by running principal component analysis (PCA), calculate the neighborhood graph of cells in PCA space, display cells in a two-dimensional UMAP embedding, and finally identify clusters of cells using Leiden clustering.
resolution = 1.5
print("PCA")
sc.tl.pca(adata, svd_solver="arpack")
print("neighbors")
sc.pp.neighbors(adata, n_neighbors=10, n_pcs=20)
print("UMAP")
sc.tl.umap(adata)
print("Leiden")
sc.tl.leiden(adata, resolution=resolution)
PCA
neighbors
UMAP
Leiden
UMAP with Leiden Clustering Labels
Here we visualize the distributions of the Leiden clusters in the UMAP plot. We see Leiden clusters tend to segregate into distinct regions within the UMAP plot.
sc.set_figure_params(figsize=(10, 10))
sc.pl.umap(adata, color=["leiden"], size=5)

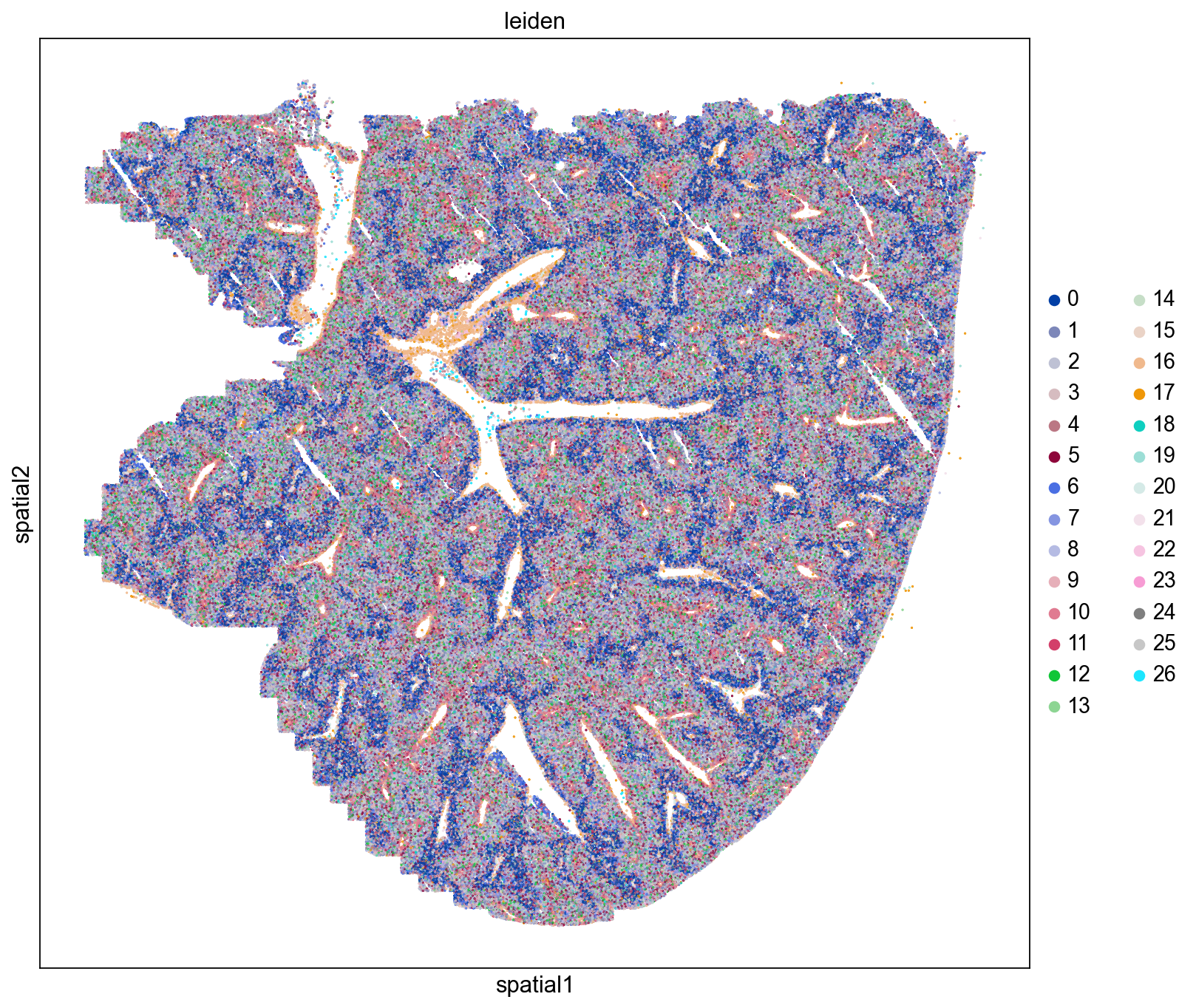
Spatial Distributions of Cells
Here we visualize the spatial locations of cells in the mouse liver colored by Leiden cluster. We observe distinct spatial localizations of Leiden clusters throughout the tissue. We see some clusters line blood vessels and while others form concentric patterns reflecting hepatic zonation (Cunningham et. al. 2021). Our next step is to assign tentative cell type to our Leiden clusters and assess their spatial localizations in the liver.
sq.pl.spatial_scatter(
adata, shape=None, color="leiden", size=0.5, library_id="spatial", figsize=(10, 10)
)
Assign Cell Types
Reference Cell Type Marker Gene Sets
In order to tentatively assign liver cell types we utilize a gene-level cell type marker reference from the publication Spatial transcriptome profiling by MERFISH reveals fetal liver hematopoietic stem cell niche architecture. These marker genes will be used to assess cell type composition of the Leiden clusters. See MERFISH gene panel metadata: https://www.nature.com/articles/s41421-021-00266-1.
gene_panel = "https://static-content.springer.com/esm/art%3A10.1038%2Fs41421-021-00266-1/MediaObjects/41421_2021_266_MOESM1_ESM.xlsx"
df_ref_panel_ini = pd.read_excel(gene_panel, index_col=0)
df_ref_panel = df_ref_panel_ini.iloc[1:, :1]
df_ref_panel.index.name = None
df_ref_panel.columns = ["Function"]
# Assign marker gene metadata using reference dataset
marker_genes = df_ref_panel[
df_ref_panel["Function"].str.contains("marker")
].index.tolist()
meta_gene = deepcopy(adata.var)
common_marker_genes = list(set(meta_gene.index.tolist()).intersection(marker_genes))
meta_gene.loc[common_marker_genes, "Markers"] = df_ref_panel.loc[
common_marker_genes, "Function"
]
meta_gene["Markers"] = meta_gene["Markers"].apply(
lambda x: "N.A." if "marker" not in str(x) else x
)
meta_gene["Markers"].value_counts()
N.A. 323
HSC marker 8
Hepatocyte marker 5
Erythroid progenitor marker 5
Macrophage marker 5
SEC marker 5
Neutrophil marker 5
MK marker 5
Potential HSC marker 5
Pre-B cell marker 5
Erythroid cell marker 4
EC marker 4
AEC marker 2
Myeloid marker 2
Macrophage/Hepatocyte marker 1
Basophil marker 1
Name: Markers, dtype: int64
Calculate Leiden Cluster Average Expression Signatures
Here we calculate the average gene expression signatures of the Leiden clusters, which will be used to assign cell type composition.
ser_counts = adata.obs["leiden"].value_counts()
ser_counts.name = "cell counts"
meta_leiden = pd.DataFrame(ser_counts)
cat_name = "leiden"
sig_leiden = pd.DataFrame(
columns=adata.var_names, index=adata.obs[cat_name].cat.categories
)
for clust in adata.obs[cat_name].cat.categories:
sig_leiden.loc[clust] = adata[adata.obs[cat_name].isin([clust]), :].X.mean(0)
sig_leiden = sig_leiden.transpose()
leiden_clusters = ["Leiden-" + str(x) for x in sig_leiden.columns.tolist()]
sig_leiden.columns = leiden_clusters
meta_leiden.index = sig_leiden.columns.tolist()
meta_leiden["leiden"] = pd.Series(
meta_leiden.index.tolist(), index=meta_leiden.index.tolist()
)
Assign Cell Type Based on Top Expressed Marker Genes
Here we assign cell type composition to the Leiden clusters by counting the frequency of cell type marker genes in the top 30 most up-regulated genes for each cluster such that cell type is assigned based on the most frequently occuring marker genes. If there is a tie in the number of marker genes, we assign the cluster to more than one cell type. Using this approach eleven Leiden clusters are assigned to be Hepatocyte containing clusters.
meta_gene = pd.DataFrame(index=sig_leiden.index.tolist())
meta_gene["info"] = pd.Series("", index=meta_gene.index.tolist())
meta_gene["Markers"] = pd.Series("N.A.", index=sig_leiden.index.tolist())
meta_gene.loc[common_marker_genes, "Markers"] = df_ref_panel.loc[
common_marker_genes, "Function"
]
meta_leiden["Cell_Type"] = pd.Series("N.A.", index=meta_leiden.index.tolist())
num_top_genes = 30
for inst_cluster in sig_leiden.columns.tolist():
top_genes = (
sig_leiden[inst_cluster]
.sort_values(ascending=False)
.index.tolist()[:num_top_genes]
)
inst_ser = meta_gene.loc[top_genes, "Markers"]
inst_ser = inst_ser[inst_ser != "N.A."]
ser_counts = inst_ser.value_counts()
max_count = ser_counts.max()
max_cat = "_".join(sorted(ser_counts[ser_counts == max_count].index.tolist()))
max_cat = max_cat.replace(" marker", "").replace(" ", "-")
print(inst_cluster, max_cat)
meta_leiden.loc[inst_cluster, "Cell_Type"] = max_cat
# rename clusters
meta_leiden["name"] = meta_leiden.apply(
lambda x: x["Cell_Type"] + "_" + x["leiden"], axis=1
)
leiden_names = meta_leiden["name"].values.tolist()
meta_leiden.index = leiden_names
# transfer cell type labels to single cells
leiden_to_cell_type = deepcopy(meta_leiden)
leiden_to_cell_type.set_index("leiden", inplace=True)
leiden_to_cell_type.index.name = None
adata.obs["Cell_Type"] = adata.obs["leiden"].apply(
lambda x: leiden_to_cell_type.loc["Leiden-" + str(x), "Cell_Type"]
)
adata.obs["Cluster"] = adata.obs["leiden"].apply(
lambda x: leiden_to_cell_type.loc["Leiden-" + str(x), "name"]
)
Leiden-0 Hepatocyte
Leiden-1 Hepatocyte
Leiden-2 Hepatocyte
Leiden-3 Hepatocyte_SEC
Leiden-4 Hepatocyte
Leiden-5 SEC
Leiden-6 Hepatocyte
Leiden-7 Hepatocyte
Leiden-8 Macrophage
Leiden-9 Hepatocyte
Leiden-10 Erythroid-cell_Erythroid-progenitor_Pre-B-cell
Leiden-11 AEC_Potential-HSC
Leiden-12 SEC
Leiden-13 Macrophage
Leiden-14 AEC_Hepatocyte
Leiden-15 SEC
Leiden-16 MK
Leiden-17 HSC
Leiden-18 Neutrophil
Leiden-19 HSC_Pre-B-cell
Leiden-20 Neutrophil
Leiden-21 HSC_Myeloid
Leiden-22 Hepatocyte_MK
Leiden-23 Hepatocyte_SEC
Leiden-24 SEC
Leiden-25 Hepatocyte
Leiden-26 Erythroid-cell_MK
Hepatocyte Zonation
Hepatocytes are the most abundant cell in the liver and have multiple roles in metabolism, endocrine production, protein synthesis, and detoxification. Hepatocytes form complex, radial structures called lobules that contain a central vein (with low blood oxygen level) surrounded by peripheral portal veins (with high blood oxygen level). Hepatocytes can also be broadly classified as peri-central or peri-portal based on their proximity to central and portal veins, respectively.
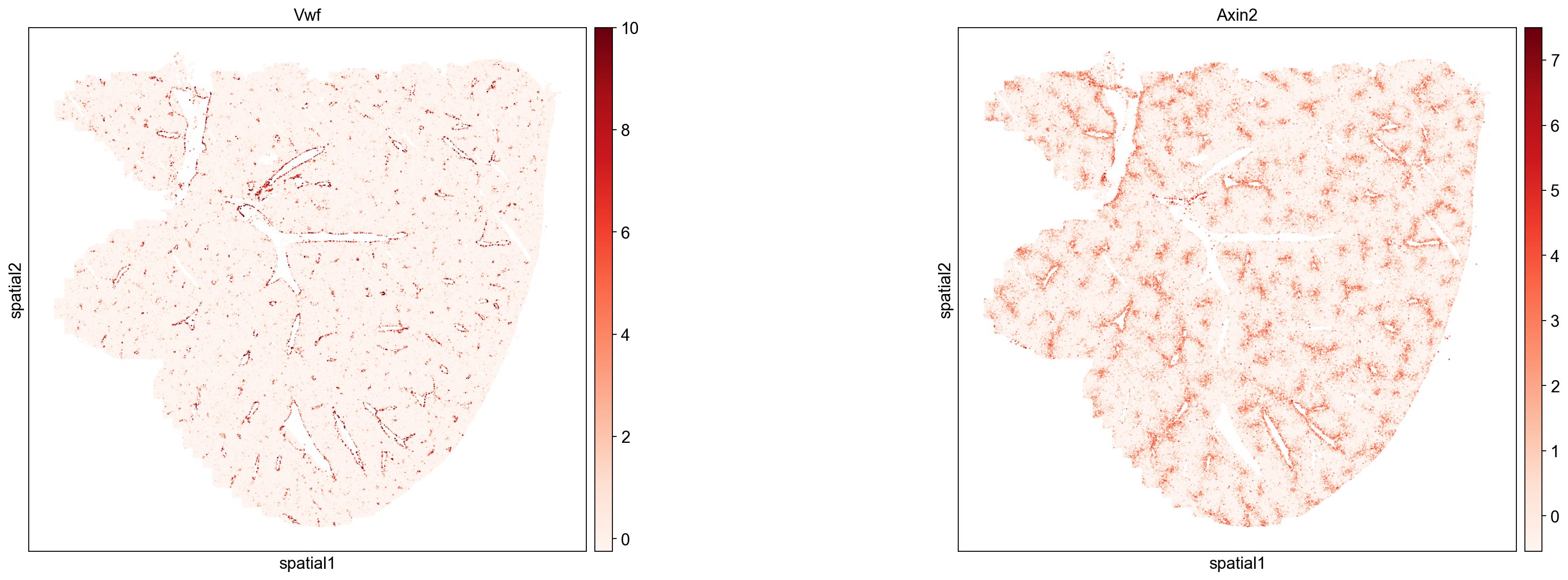
Central and Portal Blood Vessels
We can use the gene Vwf to identify endothelial cells (Horvath et. al. 2004) that line liver blood vessels. Plotting Vwf expression level in single cells (below) shows clear enrichment at blood vessel borders. Note that Vwf expression can also be used to distinguish artifactual holes/tears in the liver from blood vessels.
Next, we use the expression of Axin2 to mark peri-central regions (Sun et. al. 2020). Plotting Axin2 expression level in single cells shows Axin2 lining a subset of all Vwf positive blood vessels, which allows us to distinguish peri-portal (Axin2 negative) and peri-central (Axin2 positive) blood vessels. Similarly, we can use Axin2 expression to identify peri-central hepatocyte Leiden clusters (see next section).
sq.pl.spatial_scatter(
adata, color=["Vwf", "Axin2"], size=15, cmap="Reds", img=False, figsize=(12, 8)
)
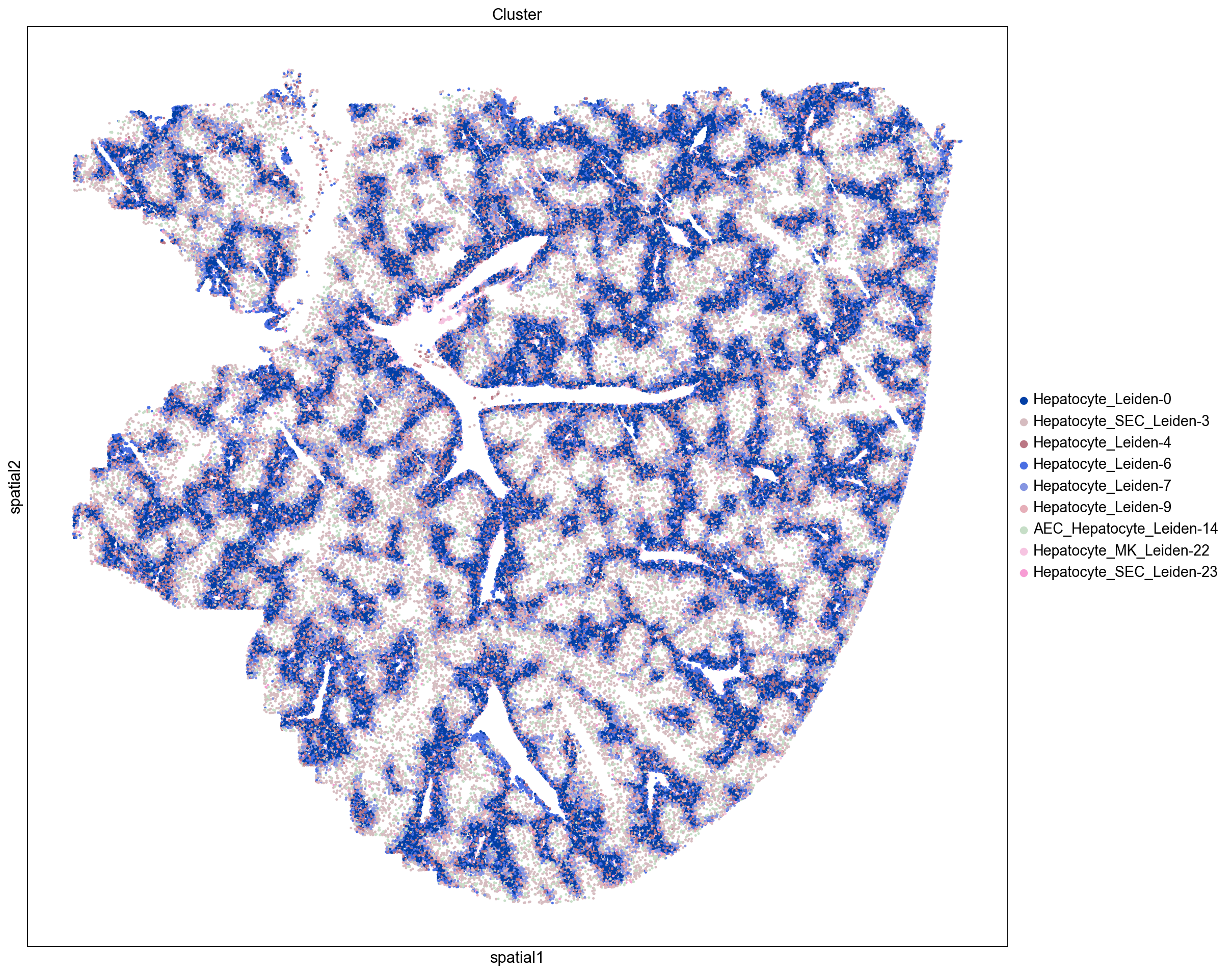
Distinguishing Peri-Portal and Peri-Central Hepatocytes
As described above, we use the expression of Axin2 as a marker for peri-central hepatocytes (see Sun et. al.).
all_hepatocyte_clusters = [x for x in meta_leiden.index.tolist() if "Hepatocyte" in x]
sig_leiden.columns = meta_leiden.index.tolist()
ser_axin2 = sig_leiden[all_hepatocyte_clusters].loc["Axin2"]
peri_central = ser_axin2[ser_axin2 > 0].index.tolist()
peri_portal = ser_axin2[ser_axin2 <= 0].index.tolist()
Peri-Central Hepatocytes
Plotting peri-central and peri-portal hepatocytes separately displays their distinct interlocking morphologies with respect to blood vessels.
sq.pl.spatial_scatter(
adata, groups=peri_central, color="Cluster", size=15, img=False, figsize=(15, 15)
)

Peri-Portal Hepatocytes
sq.pl.spatial_scatter(
adata, groups=peri_portal, color="Cluster", size=15, img=False, figsize=(15, 15)
)
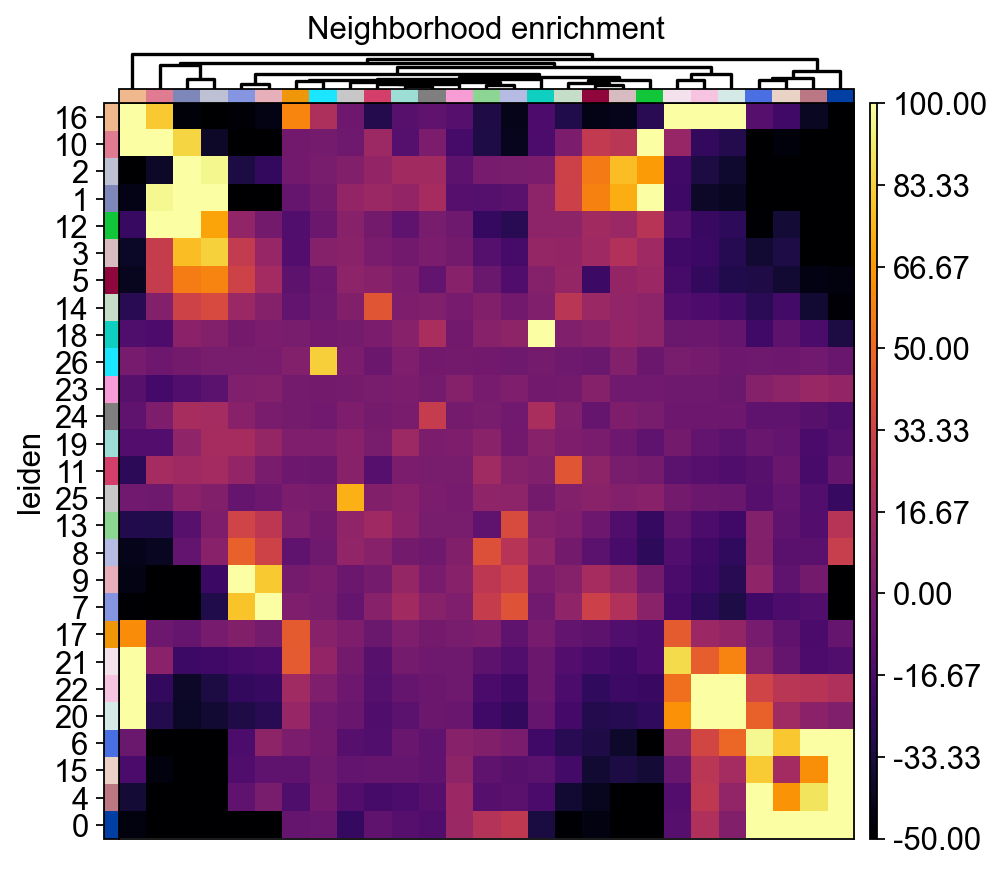
Neighborhood Enrichment
In this section we will use Squidpy to identify clusters that are spatially enriched for one another using a neighborhood enrichment test squidpy.gr.nhood_enrichment(). This test determines if cells belonging to two different clusters are close to each other more often than expected.
In order to run this test we first have to calculate a connectivity graph using the squidpy.gr.spatial_neighbors() method. This graph consists of cells (nodes) and cell-cell interactions (edges).
We also visualize the neighborhood enrichment using a hierarchically clustered heatmap which shows clusters of enriched neighborhoods in our tissue.
sq.gr.spatial_neighbors(adata, coord_type="generic", spatial_key="spatial")
sq.gr.nhood_enrichment(adata, cluster_key="leiden")
sq.pl.nhood_enrichment(
adata,
cluster_key="leiden",
method="average",
cmap="inferno",
vmin=-50,
vmax=100,
figsize=(5, 5),
)
/Users/nickfernandez/anaconda3/envs/squidpy-env/lib/python3.8/site-packages/squidpy/pl/_utils.py:582: MatplotlibDeprecationWarning: In a future version, 'pad' will default to rcParams['figure.subplot.hspace']. Set pad=0 to keep the old behavior.
col_ax = divider.append_axes("top", size="5%")
Neighborhood Enrichment Clusters
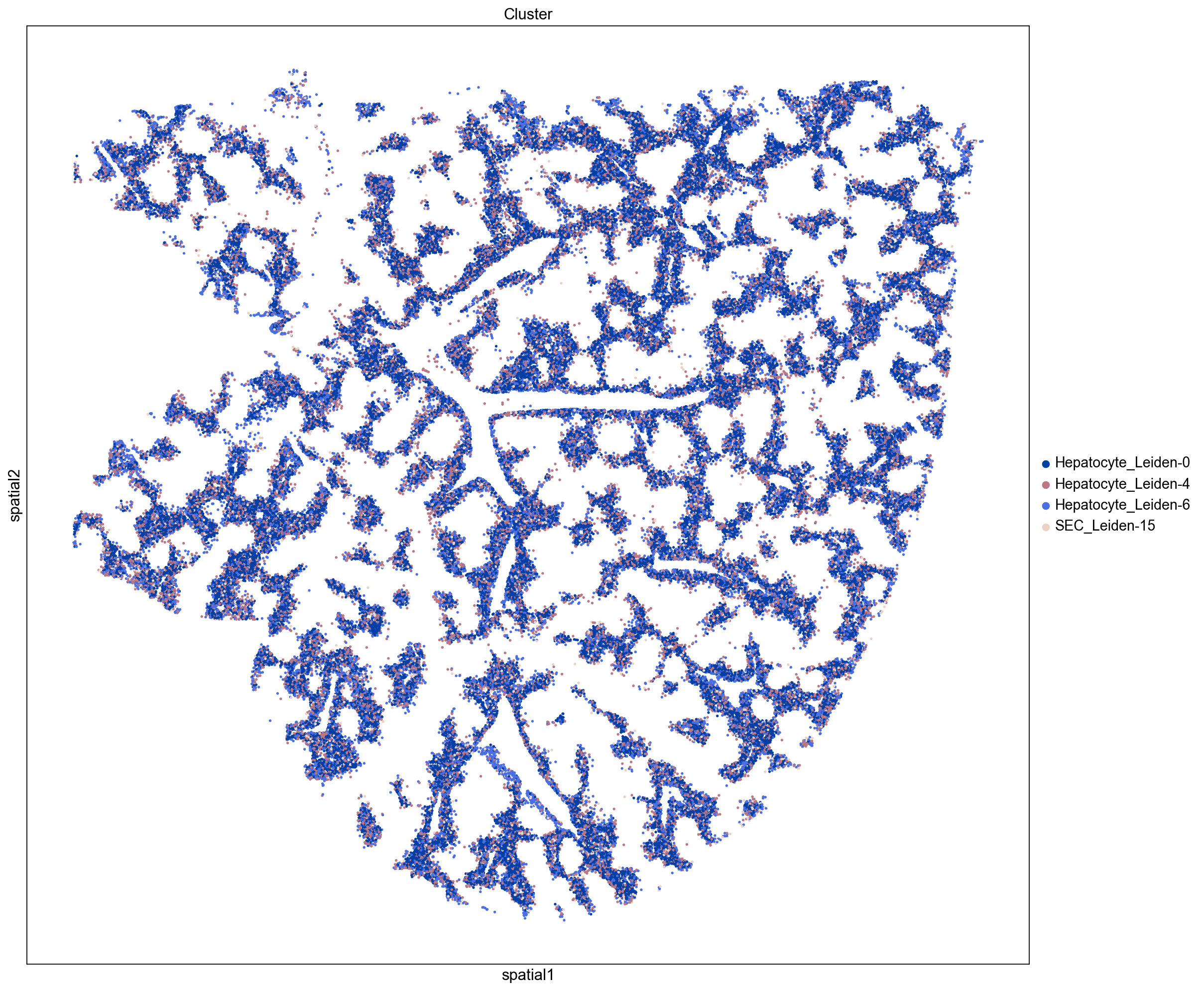
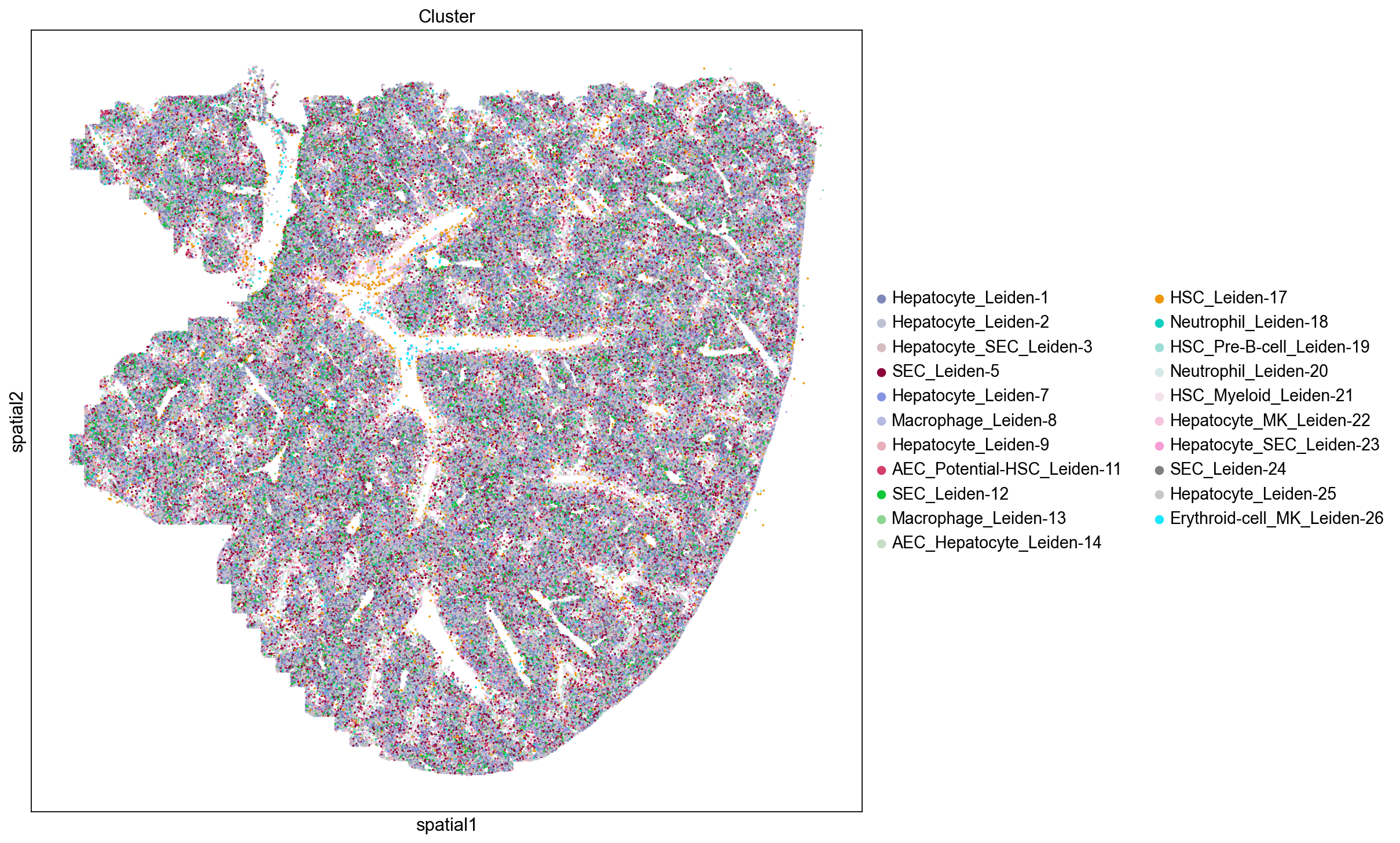
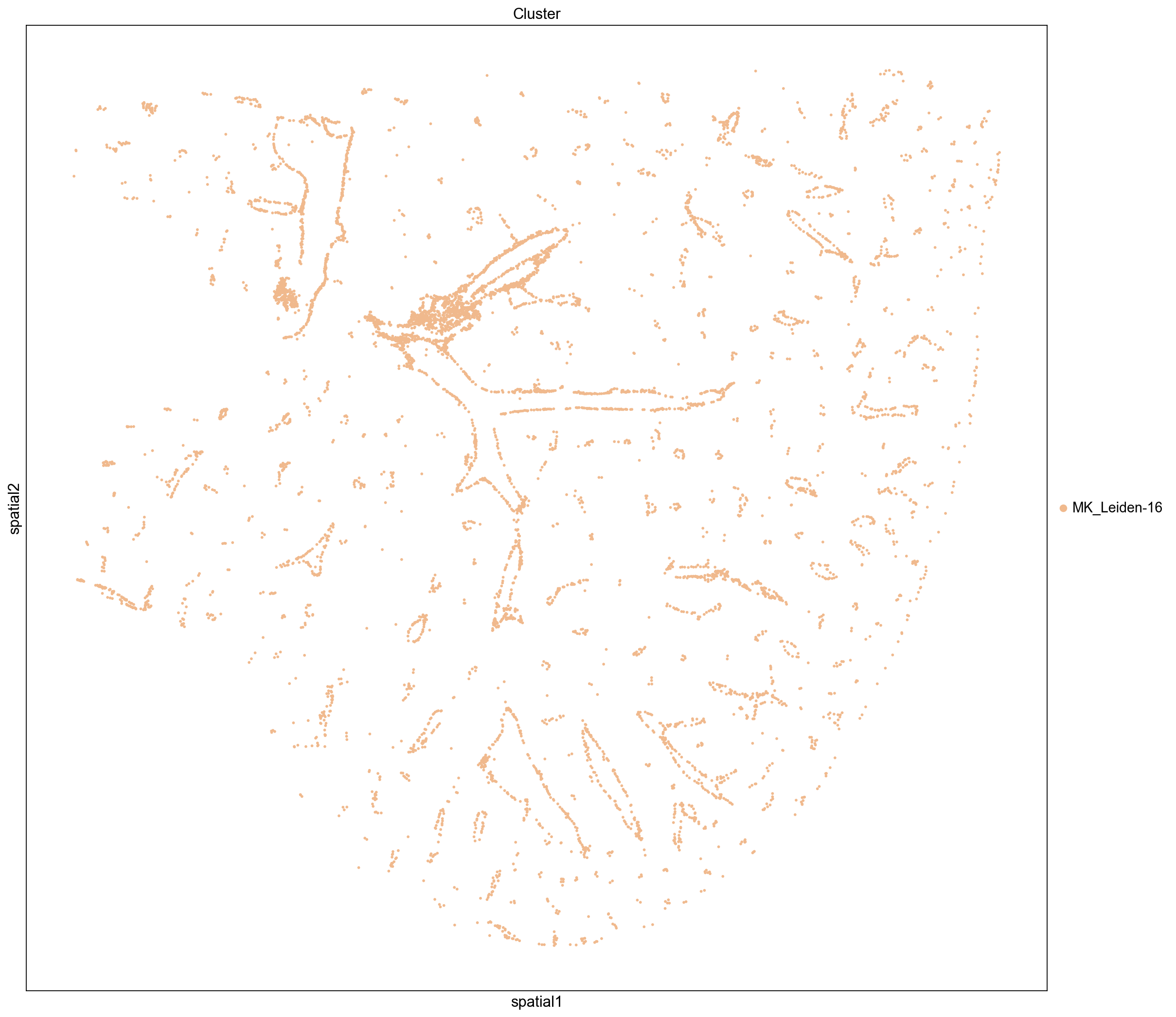
Here we visualize clusters from our neighborhood enrichment data obtained by hierarchically clustering the Z-scored neighborhood enrichment scores. We observe a cluster containing three peri-portal hepatocyte leiden clusters (Hepatocyte_Leiden-0, Hepatocyte_Leiden-4, and Hepatocyte_Leiden-6
) and a large cluster containing several peri-central hepatocytes (Hepatocyte_Leiden-1, Hepatocyte_Leiden-2, Hepatocyte_Leiden-25). This demonstrates that we can recapitulate known spatial enrichment of peri-portal and peri-central hepatocytes using neighborhood enrichment.
n_clusters = [4]
df_nhood_enr = pd.DataFrame(
adata.uns["leiden_nhood_enrichment"]["zscore"],
columns=leiden_clusters,
index=leiden_clusters,
)
nhood_cluster_levels = ["Level-" + str(x) for x in n_clusters]
linkage = sch.linkage(df_nhood_enr, method="average")
mat_nhood_clusters = sch.cut_tree(linkage, n_clusters=n_clusters)
df_cluster = pd.DataFrame(
mat_nhood_clusters, columns=nhood_cluster_levels, index=meta_leiden.index.tolist()
)
inst_level = "Level-" + str(n_clusters[0])
all_clusters = list(df_cluster[inst_level].unique())
# sc.set_figure_params(figsize=(10,10))
for inst_cluster in all_clusters:
inst_clusters = df_cluster[df_cluster[inst_level] == inst_cluster].index.tolist()
sq.pl.spatial_scatter(
adata,
groups=inst_clusters,
color="Cluster",
size=15,
img=False,
figsize=(15, 15),
)

Network Centrality Scores
In addition to neighborhood enrichment we can also calculate network-based centrality scores for the Leiden clusters. These include
closeness centrality: how close a group is to other nodes
degree centrality: fraction of connected non-group members
clustering coeffeicient: measure of the degree to which nodes cluster
sq.gr.centrality_scores(adata, "leiden")
sc.set_figure_params(figsize=(20, 8))
# copy centrality data to new DataFrame
df_central = deepcopy(adata.uns["leiden_centrality_scores"])
df_central.index = meta_leiden.index.tolist()
# sort clusters based on centrality scores
################################################
# closeness centrality - measure of how close the group is to other nodes.
ser_closeness = df_central["closeness_centrality"].sort_values(ascending=False)
# degree centrality - fraction of non-group members connected to group members.
# [Networkx](https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.centrality.degree_centrality.html#networkx.algorithms.centrality.degree_centrality)
# The degree centrality for a node v is the fraction of nodes it is connected to.
ser_degree = df_central["degree_centrality"].sort_values(ascending=False)
# clustering coefficient - measure of the degree to which nodes cluster together.
ser_cluster = df_central["average_clustering"].sort_values(ascending=False)
High Closeness Score
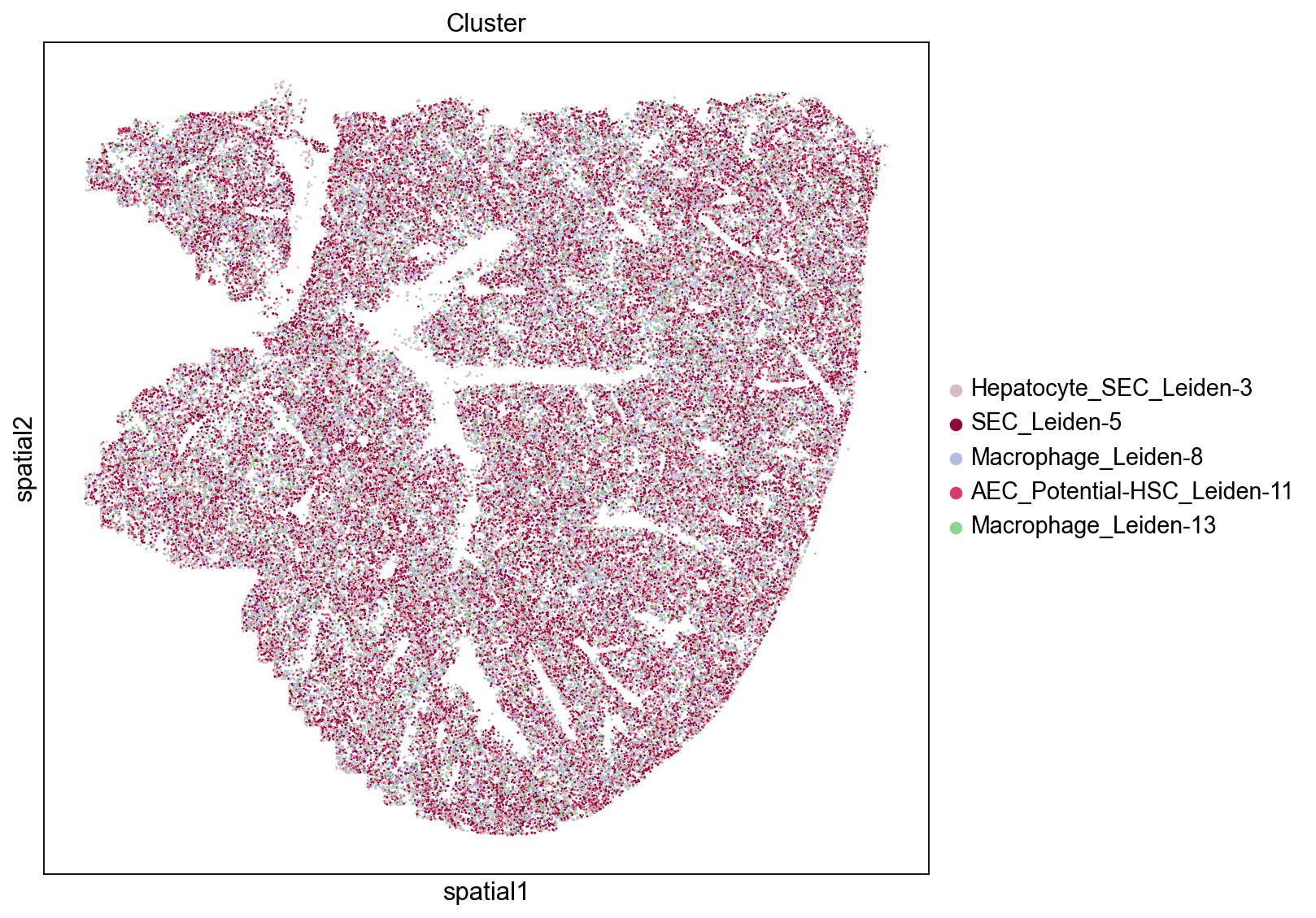
Groups/clusters with high closeness are close to other groups and will tend to display a dispersed distribution throughout the tissue. Three of the top five clusters based on the closeness score are epithelial cells (SEC: sinusoidal epithelial cells, AEC: arterial epithelial cells) and one cluster consists of macrophages. We see that these groups are indeed evenly distributed across the tissue which results in them being relatively close to many other groups.
inst_clusters = ser_closeness.index.tolist()[:5]
print(inst_clusters)
sq.pl.spatial_scatter(
adata, groups=inst_clusters, color="Cluster", size=15, img=False, figsize=(10, 10)
)
['SEC_Leiden-5', 'Hepatocyte_SEC_Leiden-3', 'Macrophage_Leiden-8', 'AEC_Potential-HSC_Leiden-11', 'Macrophage_Leiden-13']
Low Closeness Score
Groups with low closeness are not close to other groups and tend to display an uneven and isolated distribution throughout the tissue. We see that clusters with low closeness scores tend to be located near blood vessels and consist of megakaryocyte, neutrophil, and erythroid cells. Their distinct localization and proximity to blood vessel (e.g., only neighboring cells on one side while the other side faces the blood vessel) contributes to their low level of interactions with other clusters.
inst_clusters = ser_closeness.index.tolist()[-5:]
print(inst_clusters)
sq.pl.spatial_scatter(
adata, groups=inst_clusters, color="Cluster", size=15, img=False, figsize=(10, 10)
)
['SEC_Leiden-24', 'Hepatocyte_Leiden-25', 'Hepatocyte_MK_Leiden-22', 'Neutrophil_Leiden-20', 'Erythroid-cell_MK_Leiden-26']
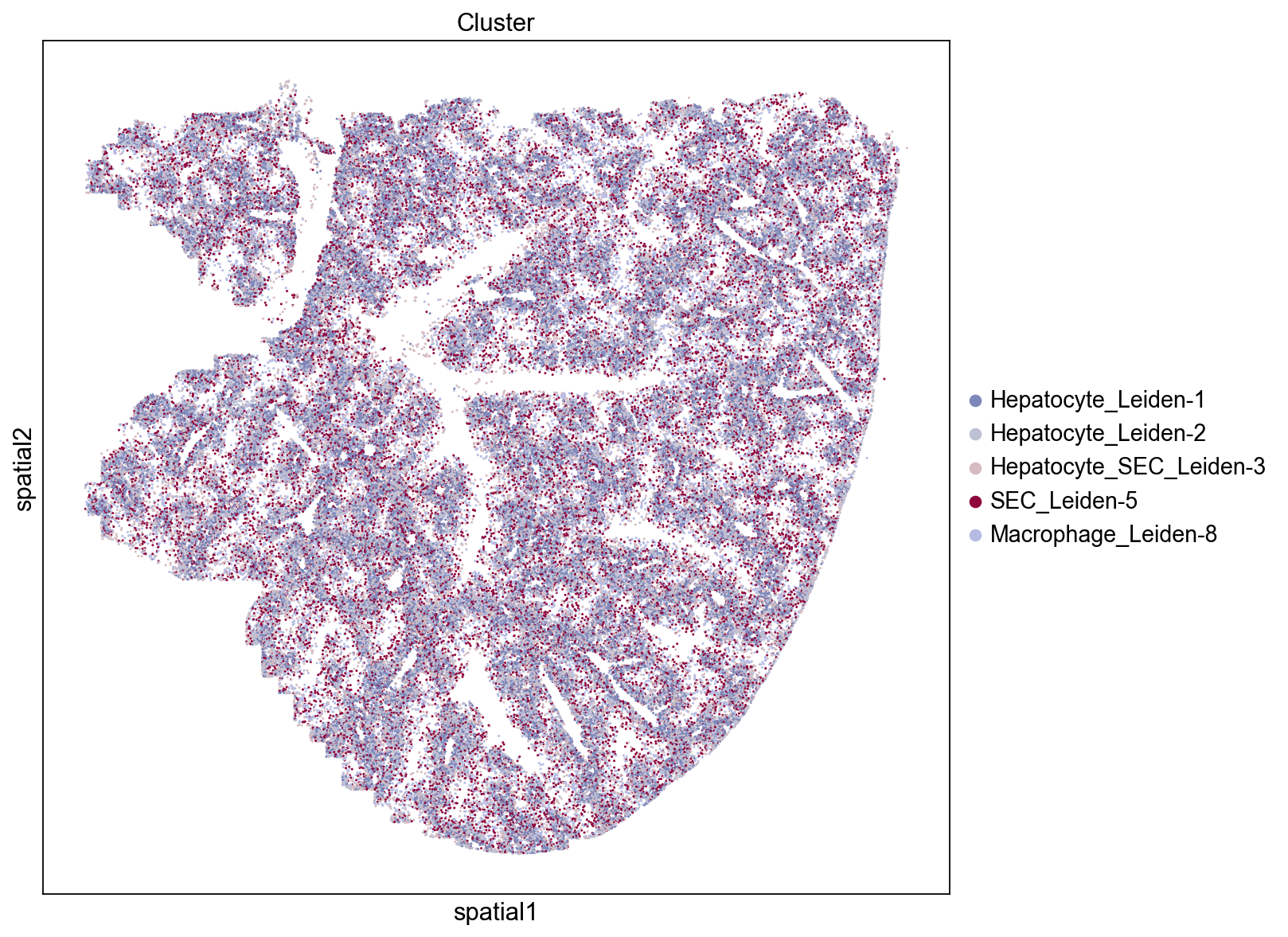
High Degree Centrality
Similarly to the results from the closeness scores we observed above, we see that the SEC and Macrophage clusters (Leiden-3, Leiden-5, and Leiden-8) have high degree centrality scores indicating that they have a high fraction of non-group member connections. We also note that these clusters tend to be more evenly distributed throughout the tissue.
inst_clusters = ser_degree.index.tolist()[:5]
print(inst_clusters)
sq.pl.spatial_scatter(
adata, groups=inst_clusters, color="Cluster", size=15, img=False, figsize=(10, 10)
)
['SEC_Leiden-5', 'Hepatocyte_SEC_Leiden-3', 'Hepatocyte_Leiden-1', 'Hepatocyte_Leiden-2', 'Macrophage_Leiden-8']
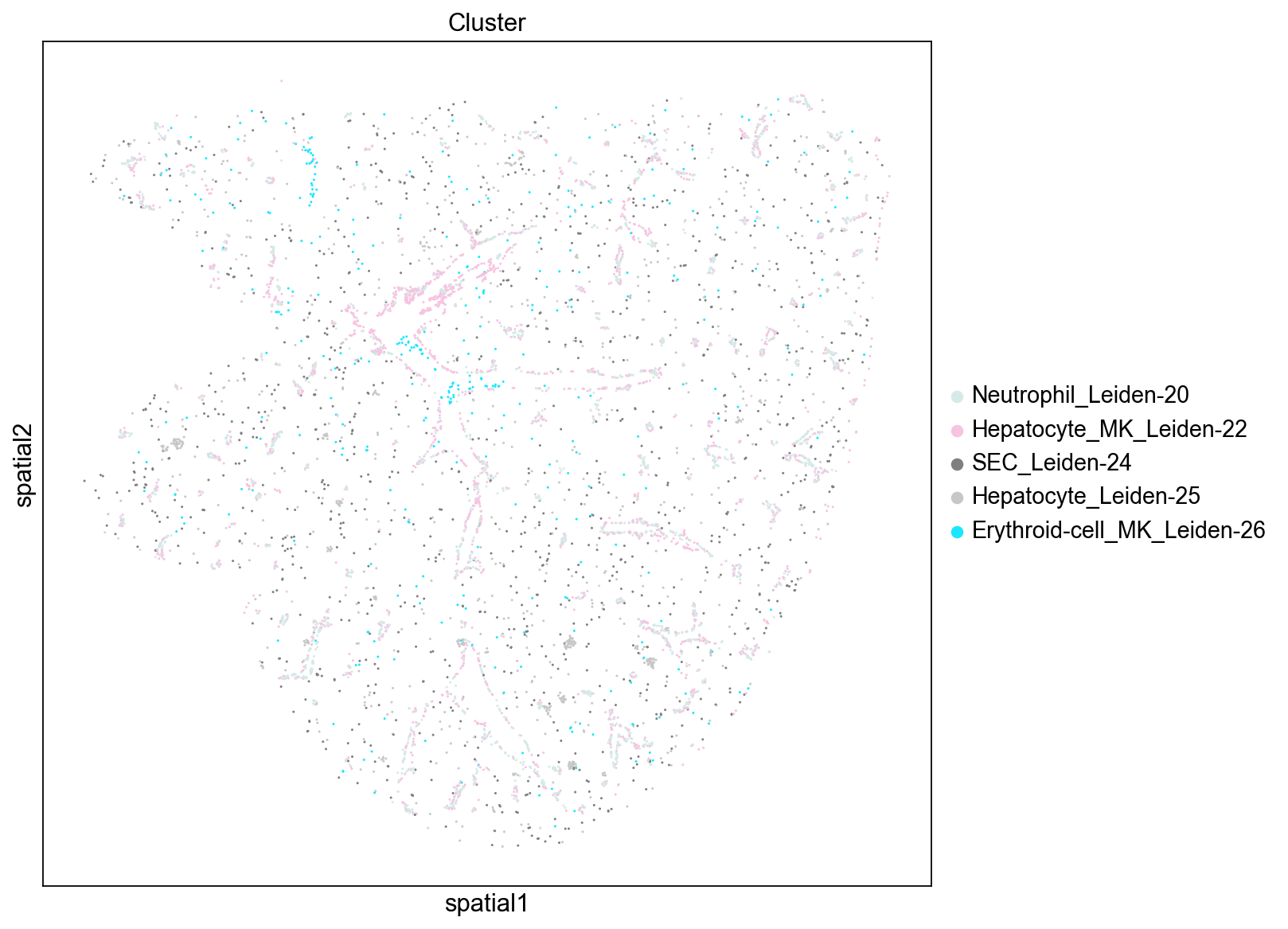
Low Degree Centrality
These cluster have particularly low non-group member connections and similarly to the results from the closeness score we see that these clusters tend to be near blood vessels. We also note that more of the clusters tend to be lower abundance clusters (Leiden cluster numbers are ranked by abundance).
inst_clusters = ser_degree.index.tolist()[-5:]
print(inst_clusters)
sq.pl.spatial_scatter(
adata, groups=inst_clusters, color="Cluster", size=15, img=False, figsize=(10, 10)
)
['Hepatocyte_SEC_Leiden-23', 'Neutrophil_Leiden-20', 'SEC_Leiden-24', 'Hepatocyte_Leiden-25', 'Erythroid-cell_MK_Leiden-26']
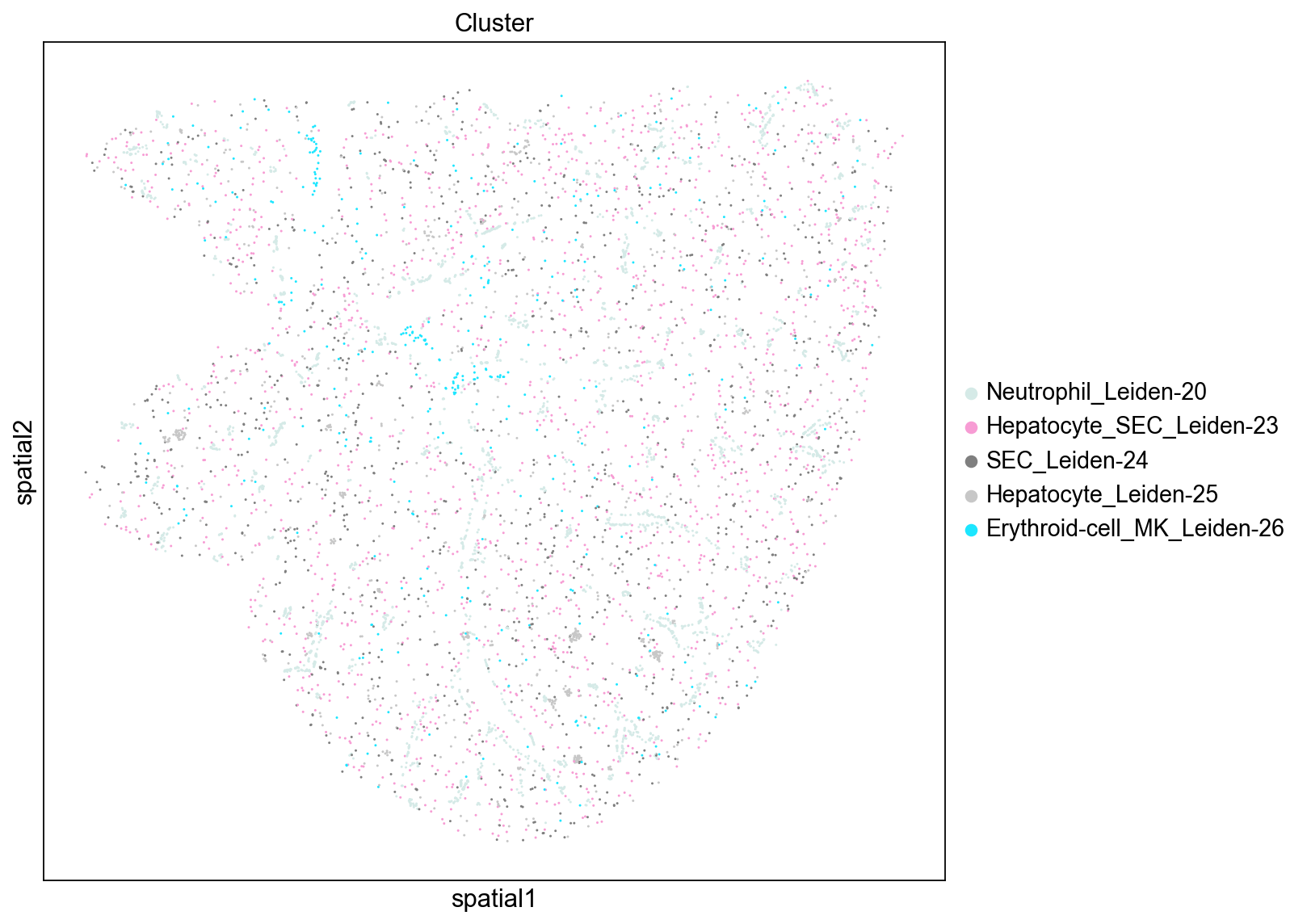
High Clustering Coefficient
The clustering coefficient indicates the degree to which nodes cluster together. We see that the top scoring clusters tend to be located near blood vessels. This distribution is somewhat counter-intuitive since one might expect that well segregated cells would form dense blobs rather than thin lines. However, their position along the edge of of blood vessels likely reduces the total number of neighbors each cell has since they are positioned at the border of a hole in the tissue.
inst_clusters = ser_cluster.index.tolist()[:5]
print(inst_clusters)
sq.pl.spatial_scatter(
adata, groups=inst_clusters, color="Cluster", size=15, img=False, figsize=(10, 10)
)
['MK_Leiden-16', 'HSC_Myeloid_Leiden-21', 'Neutrophil_Leiden-20', 'Erythroid-cell_MK_Leiden-26', 'Hepatocyte_SEC_Leiden-3']
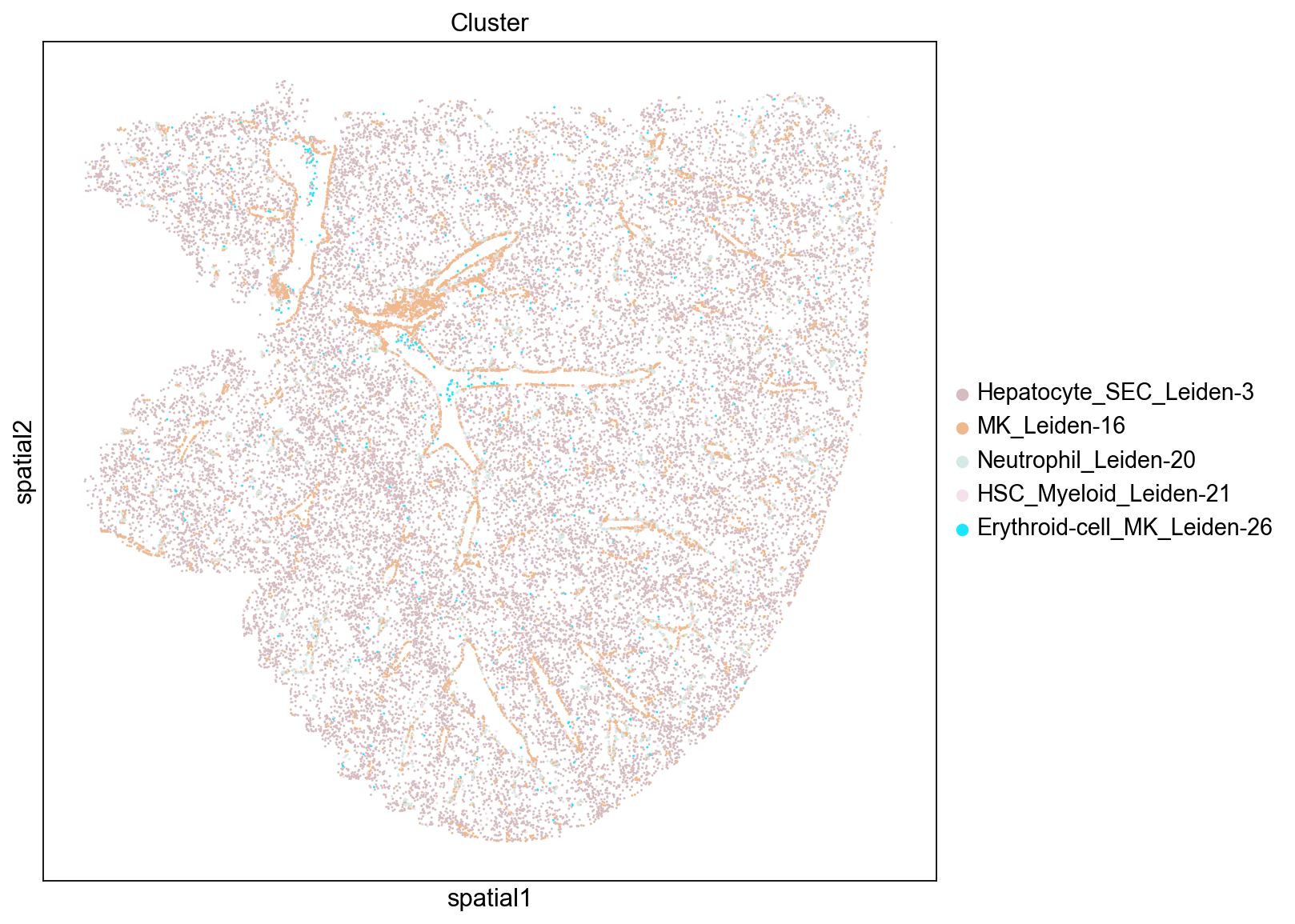
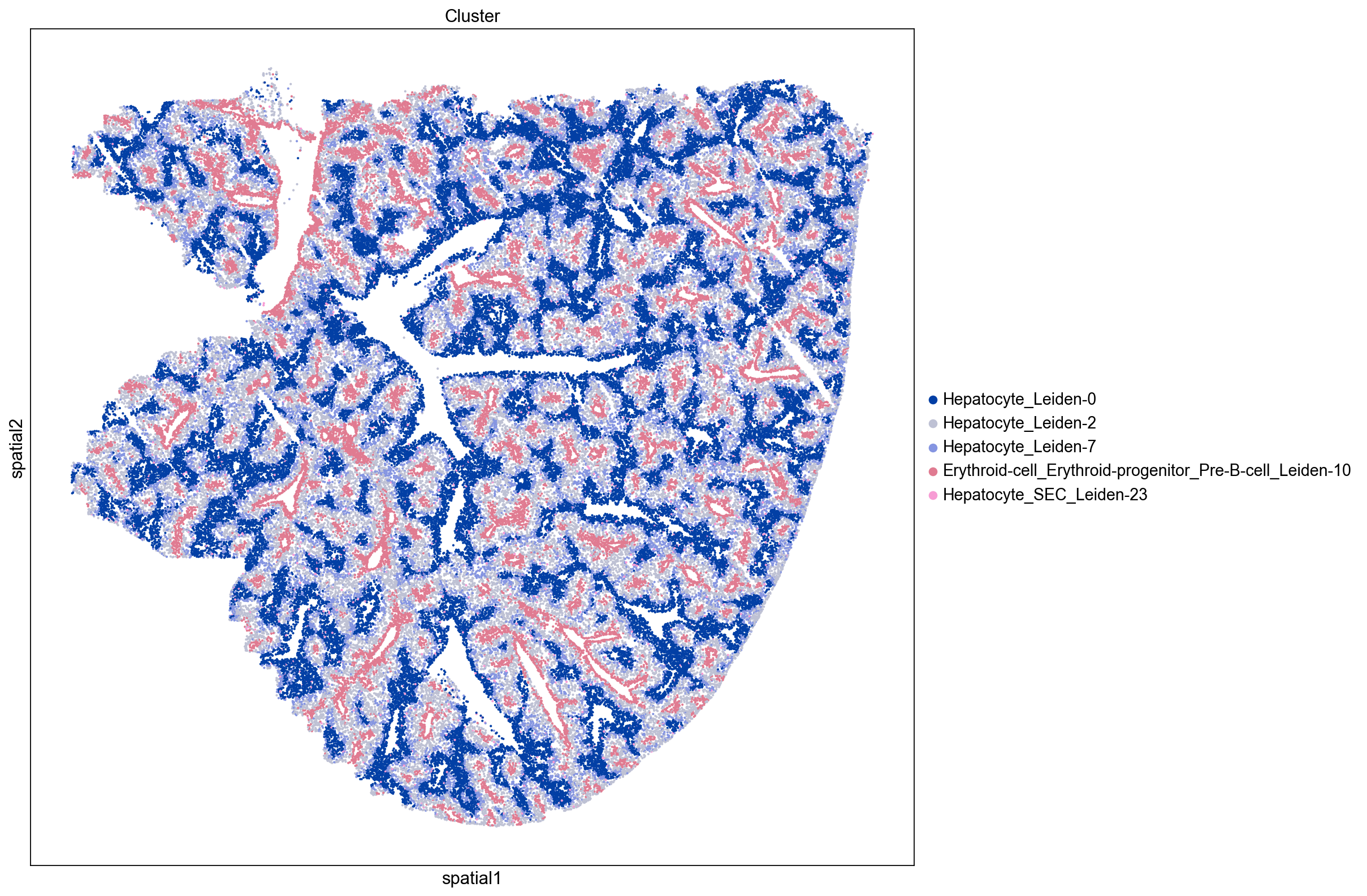
Low Clustering Coefficient
Again, we see that non-isolated groups tend to be more evenly distributed throughout the tissue. Interestingly, these clusters mostly consist of hepatocytes.
inst_clusters = ser_cluster.index.tolist()[-5:]
print(inst_clusters)
sq.pl.spatial_scatter(
adata, groups=inst_clusters, color="Cluster", size=15, img=False, figsize=(15, 15)
)
['Erythroid-cell_Erythroid-progenitor_Pre-B-cell_Leiden-10', 'Hepatocyte_Leiden-2', 'Hepatocyte_SEC_Leiden-23', 'Hepatocyte_Leiden-0', 'Hepatocyte_Leiden-7']
Autocorrelation: Moran’s I Score
Our previous focus has been mainly on the distribution of cell clusters throughout the tissue. However we can also use Squidpy to investigate the spatial distributions of genes expressed in the tissue.
Here we use Squidpy to calculate the Moran’s I global spatial auto-correlation statistic, which can be used to identify genes that are non-randomly distributed in the tissue. We will visualize the top and bottom 20 scoring genes to highlight specific examples of genes with high and low auto-correlation.
sq.gr.spatial_autocorr(adata, mode="moran")
num_view = 12
top_autocorr = (
adata.uns["moranI"]["I"].sort_values(ascending=False).head(num_view).index.tolist()
)
bot_autocorr = (
adata.uns["moranI"]["I"].sort_values(ascending=True).head(num_view).index.tolist()
)
Genes with high spatial autocorrelation
We note that many of the top scoring genes show expression patterns following the spatial pattern of hepatocyte Leiden clusters (e.g. Aldh1b1, Aldh3a20) and blood vessels (e.g. Dpt, Sfrp1). We can also check which cell types are most associated with these highly auto-correlated genes by ranking cell clusters based on their expression of these genes (e.g. mean expression). Below we see that three of the top five cell clusters are hepatocytes, which agrees with the gene’s localization patterns. These results indicate the primary spatial patterns in gene expression auto-correlation are being driven by their expression in hepatocytes and blood vessel associated cell types.
sq.pl.spatial_scatter(
adata, color=top_autocorr, size=20, cmap="Reds", img=False, figsize=(5, 5)
)
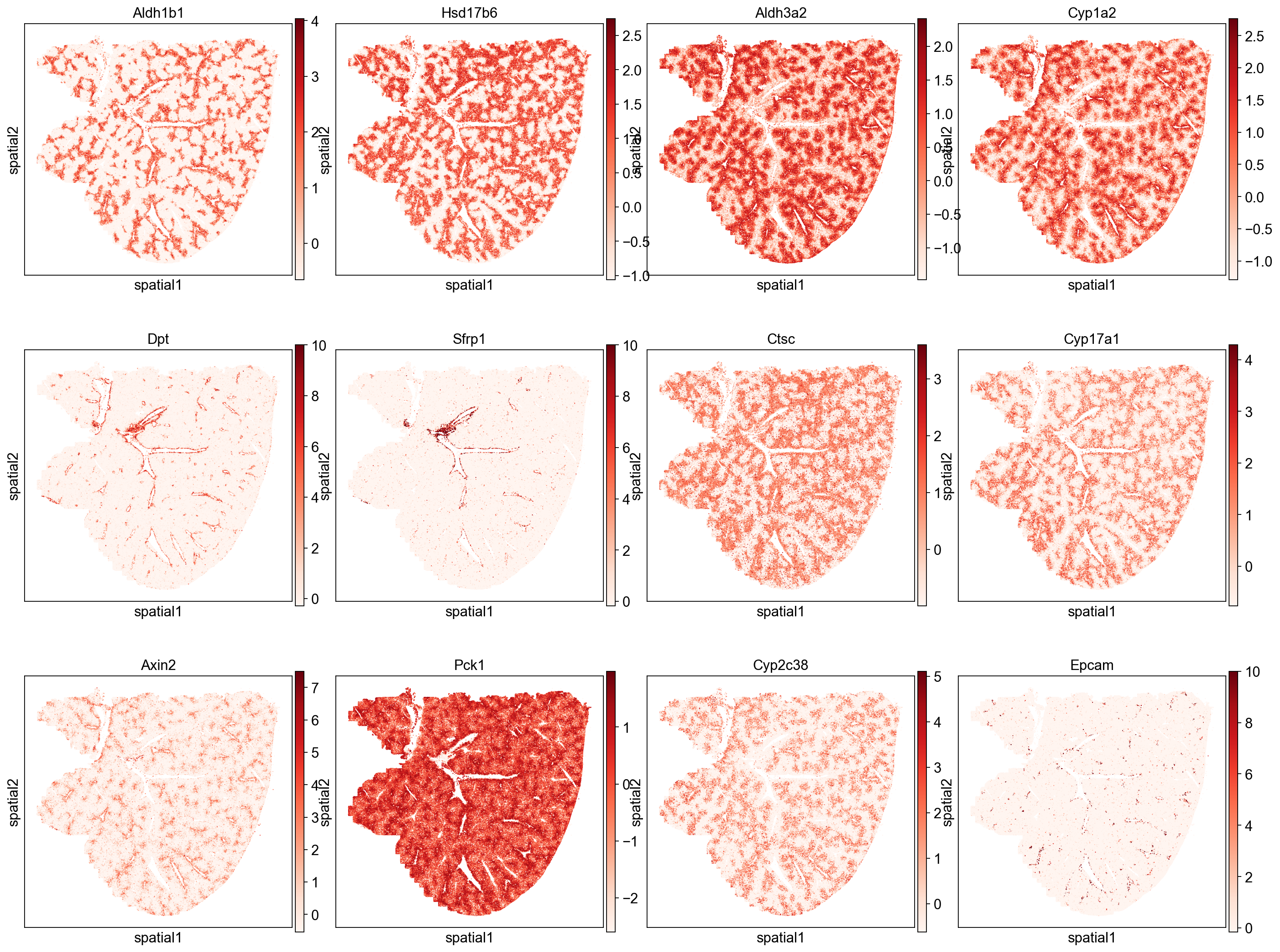
# top cell types based on average expression of top_autocorr genes
sig_leiden.loc[top_autocorr].mean(axis=0).sort_values(ascending=False).index.tolist()[
:5
]
['Neutrophil_Leiden-20',
'Hepatocyte_MK_Leiden-22',
'Erythroid-cell_Erythroid-progenitor_Pre-B-cell_Leiden-10',
'Hepatocyte_Leiden-0',
'Hepatocyte_Leiden-6']
Genes with low autocorrelation
Genes with low auto-correlation show more evenly distributed expression patterns that do not follow hepatic zonation.
sq.pl.spatial_scatter(
adata, color=bot_autocorr, size=20, cmap="Reds", img=False, figsize=(5, 5)
)
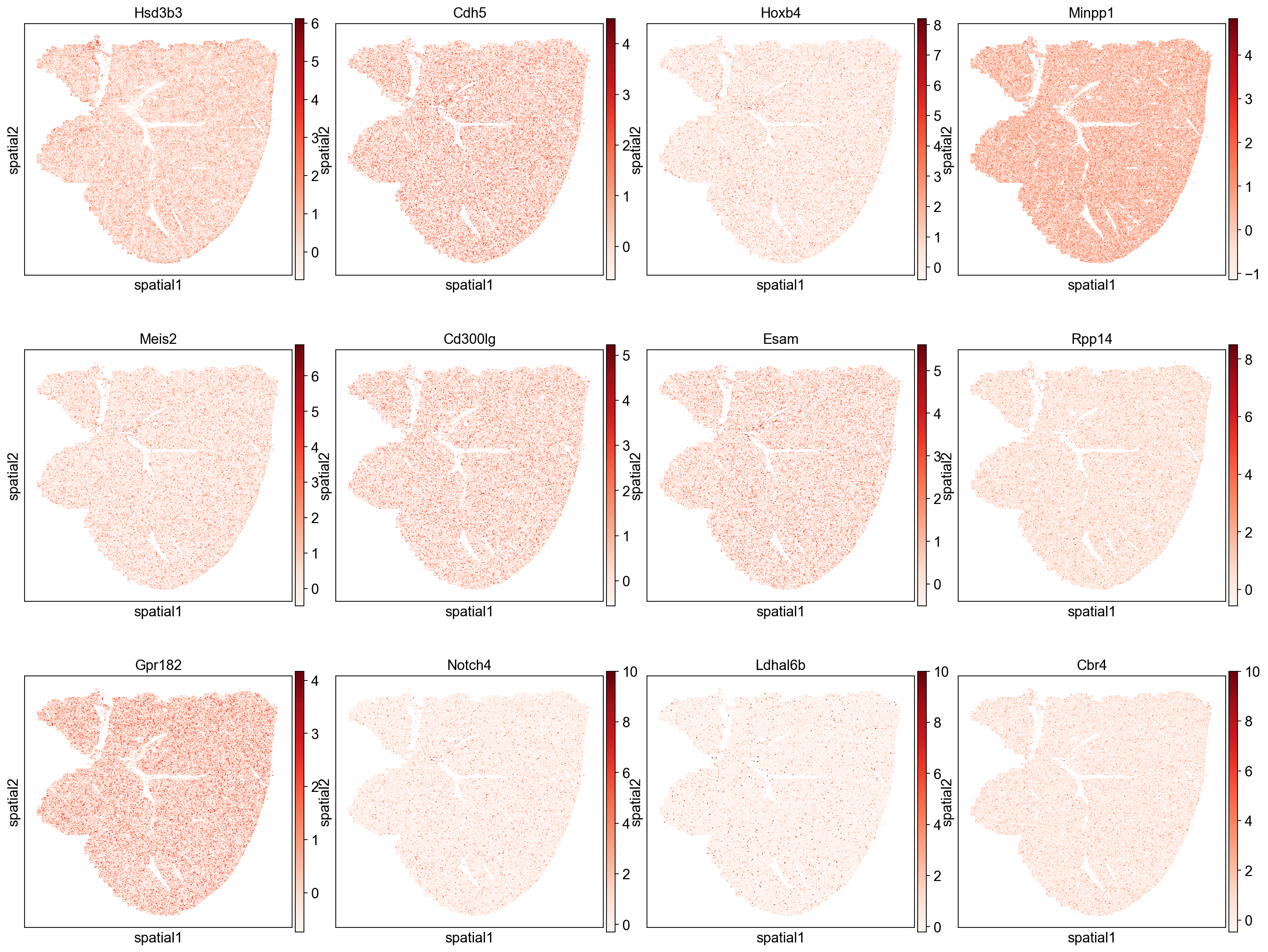
# top cell types based on average expression of bot_autocorr genes
sig_leiden.loc[bot_autocorr].mean(axis=0).sort_values(ascending=False).index.tolist()[
:5
]
['SEC_Leiden-5',
'SEC_Leiden-15',
'SEC_Leiden-24',
'MK_Leiden-16',
'Hepatocyte_SEC_Leiden-23']
Conclusion
This tutorial shows how we can use Squidpy and Scanpy to explore the spatial distribution of single-cells and gene expression in mouse liver tissue from Vizgen’s MERFISH Mouse Liver Map. One of the main highlights is the intricate hepatic zonation patterns and their relationship to portal/central veins in the mouse liver.